
語彙選定について
1.各国提出データの概要
①日本側データ:4,569語
元データ:独立行政法人国立国語研究所
「現代雑誌200万字言語調査語彙表」(2001年度~2005年度実施)
http://www.ninjal.ac.jp/archives/goityosa/
語彙表ファイル
度数順語彙表 (自立語)
抽出作業
・漢語だけを抽出。
・平仮名表記のものに対して、漢字表記に変換
*「あいさつ」などに対して、「挨拶」を入れた。
・次のものを削除
*語として認めがたいもの。テンハチ「.8」などの記号、数字など。
*社名などの固有名詞。
*漢字1字語。
*2桁の漢数字。「二十」など
・漢字表記(2字・3字語)を1字に分解
②韓国側データ:6,415語
元データ:
2002年,2005年 国立国語院『現代国語使用頻度調査』
1995年,『韓国語口数使用頻繁調査』
抽出基準
(1)固有語を除く
(2)(名詞)ハングル語を除く:그녀(그女), 정말(正말), 달력(달層)
(3)(動詞)漢語1文字のものを除く:위하다(寫하다), 속하다(屬하다), 정하다(定하다), 변하다(變하다)
③中国側データ:3,107語
元データ:
『現代漢語頻率詞典』
中国側提出データは3,184語であったが、4字以上のデータがあったため、削除。
2.統合のためのデータ整理
2-1.字体を「簡体字」に変換
・日本漢字⇒簡体字
・韓国繁体字⇒簡体字
*変換ツールは以下のサイトを使用したが、正確に変換されない字もあったため、全データを目視でチェック
Kanconvit – 簡体字と日本語漢字の相互変換ツール
http://kanconvit.ta2o.net/
http://kanconvit.ta2o.net/conv.cgi
日中情報コミュニティサイト 簡体字・繁体字変換
http://www.jcinfo.net/jp/bigbg/
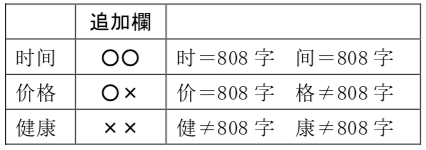
2-2.共通漢字808字が含まれている語かどうかをチェック
上記各国①②③の表に、○×による欄を追加。
3.統合作業
MS-Accessに2の各国のデータをインポートし、「簡体字」をキーに突合。
4.突合結果
三カ国共通:995語が抽出できた。
5.600語程度に絞り込み
条件1.808字が含まれない語は除く。
条件2.
日本データ頻度数8以上
韓国データ頻度数4以上
中国データ順位626以下
658語が選択できた。