
어휘 선정 대해
1. 각국이 제출한 데이터의 개요
1) 일본측 데이터 : 4,569자
원데이터: 독립행정법인 국립국어연구소
「현대잡지 200만자 언어조사어휘집」(2001년~2005년 실시)
http://www.ninjal.ac.jp/archives/goityosa/
어휘표파일
도수순 어휘표(자립어)
추출작업
・한자어만 추출
・히라나가 표기를 한자 표기로 변환
* ‘あいさつ(아이사츠; 히라가나로 주로 표현)’ 등을 ‘挨拶’로 표기
・아래의 사항을 삭제
* 단어로 인정하기 어려운 것들(숫자 등)
* 회사명 등 고유명사
*1음절 한자어
2) 한국측 데이터: 6,415자
원데이터: 국립국어원 ‘현대국어사용빈도조사’ (2002, 2005)
추출작업
(1)한자어만 추출
(2)고유어, 혼성어(그女, 正말 등) 제외
(3)음절 한자어, 어근(定하다, 屬하다 등) 제외
3) 중국측 데이터: 3,107자
원데이터: 현대한자어빈솔사전
* 중국 측 제출 자료는 3,184자 였지만 4자 이상의 데이터가 있었으므로 삭제
2. 통합을 위한 데이터 정리
1) 모든 한자를 간체자로 변환
・일본 한자 간체자
・한국 정체자 간체자
*변환 도구는 다음의 사이트를 사용하였으나 정확하게 변환되지 않는 한자도 있었으므로 모든 데이터를 눈으로 체크함.
Kanconvit – 간체자와 일본 한자 상호변환 도구
http://kanconvit.ta2o.net/
http://kanconvit.ta2o.net/conv.cgi
일본/중국 정보 커뮤니티 사이트 간체자/정체자 변환
http://www.jcinfo.net/jp/bigbg/
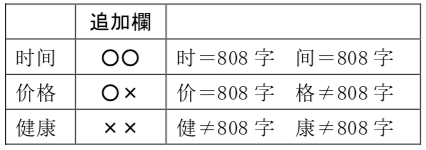
2) 공통한자 808자가 포함되어있는지의 여부를 체크
각국에서 추출한 표에 OX란을 따로 추가
3. 통합작업
MS-Access에 <2>의 각국 데이터를 입력하여 ‘간체자’를 키에 대조하였음
4. 대조 결과
3국 공통 995개 단어를 추출하였음
5. 658개 단어 추출 기준
조건 1) 한중일 공동상용 808 한자가 포함되지 않는 단어는 제외
조건 2) 일본 데이터 빈도수 8 이상, 한국 데이터 빈도수 4 이상, 중국 데이터 순위 626 이하
결과: 658개 단어 선정